IT аутсорсинг
IT аутстаффинг
Разработка сайтов
Программные модули
Разработка приложений
Сопровождение
Боты и утилиты
Сервисы
Все услуги

Каталог услуг
IT аутсорсинг
IT аутстаффинг
Разработка сайтов
Программные модули
Разработка приложений
Сопровождение
Боты и утилиты
Сервисы
Все услуги
Время прочтения: 10 минут
Дата публикации: 12.03.2026
 Поделиться
Поделиться
Техническая поддержка сайта часто превращается в «серую зону»: заявки уходят в мессенджеры, сроки плавают, а результат сложно измерить. В итоге бизнес платит за обслуживание web сайта, но не понимает, за что именно — и почему очередная проблема «решается завтра».
SLA (Service Level Agreement) помогает перевести поддержку и обслуживание сайтов из режима «как получится» в понятный сервис: фиксируются метрики, приоритеты, правила коммуникации и ответственность сторон. В крупных экосистемах SLA давно стал нормой: например, в регламентах техподдержки отдельно описывают время реакции, режим работы и условия обработки инцидентов по критичности. А также подчеркивают, что сроки решения могут зависеть от третьих сторон и входных данных от клиента — это важно корректно прописывать в договоре.
Если вам нужна техническая поддержка сайта как управляемая услуга (а не «попробуем помочь»), ниже — практический разбор: какие показатели включать в SLA и как реально контролировать подрядчика.
В контексте услуг Focus IT:
Если вы хотите выстроить поддержку и сопровождение сайта по понятным правилам — начните с услуги Техническая поддержка.
Если параллельно планируется улучшение функционала и скорости — логично связать SLA с работами по Модернизации и доработке сайта.
SLA — это соглашение об уровне сервиса между заказчиком и исполнителем. В нем описывают:
какие работы входят в поддержку сайта (и что не входит);
в какие часы оказываются услуги;
какие метрики считаются нормой (время реакции, восстановление, доступность);
как считается нарушение SLA и что происходит при нарушении.
С практической точки зрения SLA решает три задачи:
Перед тем как писать цифры, договоритесь о терминах и способах измерения. Иначе «реакция была» превратится в «мы прочитали сообщение в Telegram».
1) Время реакции (Time to Respond)
Что это: время от поступления обращения до первого подтвержденного ответа/взятия в работу в официальном канале (тикет/почта/портал).
Зачем: показывает, насколько подрядчик вообще «на связи» и не теряет обращения.
Как фиксировать: только через сервис‑деск/тикет‑систему или почту с авто‑регистрацией заявки. В некоторых SLA прямо прописывают, какие каналы считаются официальными и как считается момент поступления.
2) Время восстановления (MTTR / Time to Restore)
Что это: время от регистрации инцидента до восстановления работоспособности (или обходного решения).
Зачем: бизнесу важнее «сайт снова продает», чем «мы нашли причину».
Важно: разделите:
восстановление сервиса (быстро вернуть работу);
устранение первопричины (пост‑анализ, фиксы, релиз).
3) Время решения (Time to Resolve)
Что это: полный цикл до окончательного решения и закрытия тикета (с документированием, фиксом, тестом).
Зачем: защищает от ситуации «подняли, но через час снова упало».
4) Доступность (Uptime, %)
Что это: процент времени, когда сайт/ключевые функции доступны.
Зачем: особенно критично для eCommerce и лидогенерации.
Как считать: заранее прописать:
что считается «простоем»;
какие страницы/функции измеряются (главная/каталог/корзина/оплата/админка);
инструмент мониторинга (например, внешние проверки каждые N минут).
5) Доля соблюдения SLA (SLA Compliance, %)
Что это: сколько обращений обработано в срок по каждой категории приоритета.
Зачем: сводный KPI по поддержке и обслуживанию сайтов — удобно для ежемесячных отчетов.
Без приоритетов SLA не работает: все заявки будут «срочно». Поэтому в договоре фиксируют категории и примеры.
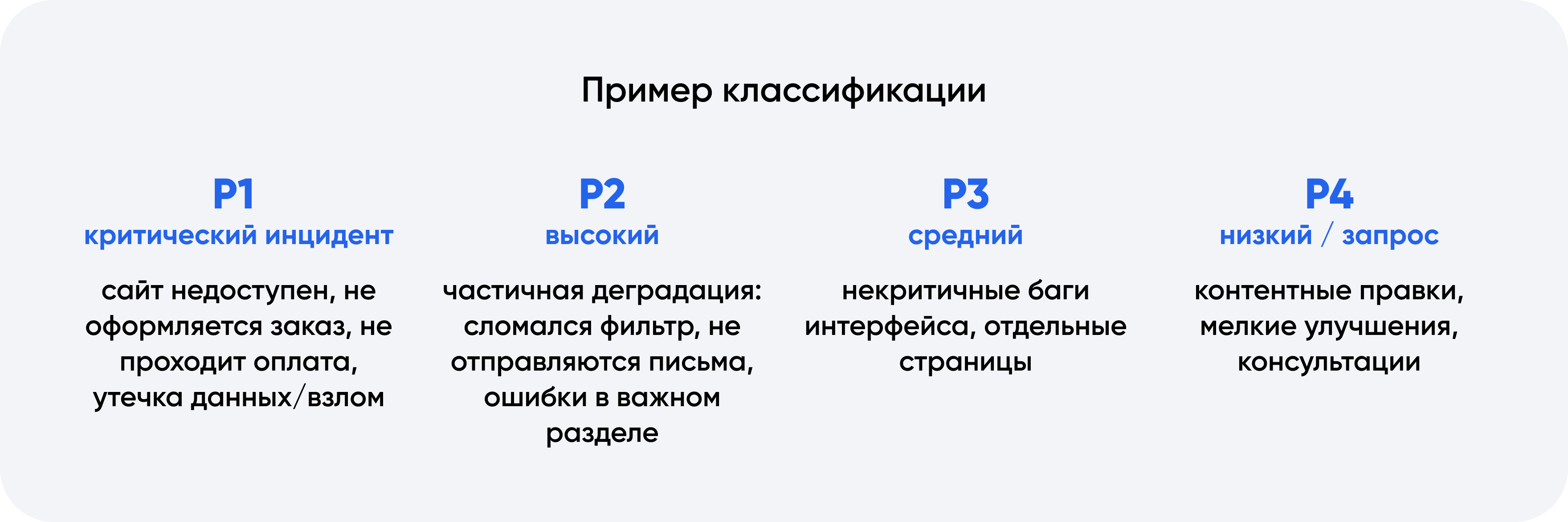
Пример классификации
P1 (критический инцидент): сайт недоступен, не оформляется заказ, не проходит оплата, утечка данных/взлом.
P2 (высокий): частичная деградация: сломался фильтр, не отправляются письма, ошибки в важном разделе.
P3 (средний): некритичные баги интерфейса, отдельные страницы.
P4 (низкий / запрос): контентные правки, мелкие улучшения, консультации.
Отдельно пропишите: кто имеет право ставить P1 и как происходит переквалификация при злоупотреблениях.
Один из частых конфликтов — «почему вы не отвечаете ночью». В SLA нужно указать:
часы работы поддержки (например, 9:00–18:00 МСК);
что считается рабочими часами при расчете времени реакции;
есть ли «экстренная поддержка» и по каким инцидентам.
Такую логику часто используют в регламентах поддержки: отдельно выделяют стандартное окно и экстренное, а время реакции зависит от критичности.

1) Каналы коммуникации и «официальная заявка»
Пропишите: какие каналы считаются официальными (почта, тикет‑система), а какие — неофициальными (мессенджеры для уведомлений). Это защищает от «вы же писали в личку».
2) Состав работ: что входит в техническое обслуживание сайта
Разделите на:
инциденты (поломки);
регламентные работы (обновления, бэкапы, мониторинг);
развитие (новые функции, доработки — обычно отдельная оценка).
3) Зависимости от третьих сторон
Хостинг, платежи, API, облачные сервисы. В регламентах прямо отмечают, что часть сроков может зависеть от третьих сторон и своевременных ответов клиента. Это нужно учесть, но не превращать в «универсальную отмазку» — уточните механизм фиксации таких пауз.
4) Обязательства заказчика
Например: доступы, контактные лица, сроки предоставления информации, правила согласования релизов.

1) Каналы коммуникации и «официальная заявка»
Пропишите: какие каналы считаются официальными (почта, тикет‑система), а какие — неофициальными (мессенджеры для уведомлений). Это защищает от «вы же писали в личку».
2) Состав работ: что входит в техническое обслуживание сайта
Разделите на:
инциденты (поломки);
регламентные работы (обновления, бэкапы, мониторинг);
развитие (новые функции, доработки — обычно отдельная оценка).
3) Зависимости от третьих сторон
Хостинг, платежи, API, облачные сервисы. В регламентах прямо отмечают, что часть сроков может зависеть от третьих сторон и своевременных ответов клиента. Это нужно учесть, но не превращать в «универсальную отмазку» — уточните механизм фиксации таких пауз.
4) Обязательства заказчика
Например: доступы, контактные лица, сроки предоставления информации, правила согласования релизов.
Чтобы техническая поддержка и сопровождение сайта были управляемыми, контроля «на словах» недостаточно.
1) Только через тикет‑систему (Service Desk)
Минимум, который нужен для контроля:
регистрация всех обращений;
автоматическое измерение сроков SLA;
история действий;
статусы и исполнители.
2) Ежемесячная отчетность по SLA
Попросите фиксированный шаблон отчета:
количество тикетов по P1–P4;
% соблюдения SLA по каждой категории;
среднее/медианное время реакции и восстановления;
топ‑причины инцидентов;
что было сделано в рамках профилактики.
3) Постмортемы по P1 (разборы инцидентов)
Для критических падений требуйте короткий документ:
что произошло;
влияние на бизнес;
как восстановили;
первопричина;
план предотвращения повторения (и сроки).
4) Контроль профилактики (а не только «тушение пожаров»)
В SLA/приложении пропишите регламентные задачи:
резервные копии (частота, срок хранения, тест восстановления);
обновления CMS/плагинов;
мониторинг сертификатов и доменов;
сканирование уязвимостей (по договоренности).
Если в SLA нет ответственности — это чаще декларация. На практике используют:
сервис‑кредиты (скидка/компенсация на следующий период);
штрафы за систематические нарушения по P1/P2;
право расторжения при N нарушениях подряд.
Важно: делайте ответственность соразмерной и привязанной к реальным метрикам из тикет‑системы.
Есть регламент профилактики: бэкапы, обновления, мониторинг.
Что выбрать бизнесу: «жесткий SLA» или «разумный SLA»
Слишком жесткий SLA без ресурсов приведет к формальному соблюдению сроков и ухудшению качества. Слишком мягкий — не даст контроля. Лучший подход для большинства компаний:
жестко фиксировать P1/P2 (инциденты, влияющие на деньги и репутацию);
по P3/P4 оставлять разумные окна и планирование в спринтах/пакетах часов.
Хотите SLA, который реально работает?
Если вам нужна техническая поддержка вашего сайта с прозрачными сроками реакции и восстановления — мы поможем:
провести аудит текущего обслуживания;
предложить уровни SLA под вашу нагрузку и бизнес‑критичность;
выстроить процессы через тикеты и регулярную отчетность.
Содержание
Автор статьи

Остались вопросы?
Оставьте заявку, и наши специалисты свяжутся с вами
Эффективный SLA предусматривает регрессивную шкалу оплаты: при снижении аптайма или превышении времени реакции стоимость услуг за месяц уменьшается на фиксированный процент. Это мотивирует подрядчика соблюдать сроки и оперативно выделять ресурсы на устранение критических инцидентов.
Для контроля используют системы мониторинга (UptimeRobot, Pingdom) для проверки доступности сайта и данные из таск-трекеров (Jira, YouTrack). Подрядчик обязан предоставлять ежемесячный отчет, где сравниваются фактические показатели времени решения задач с нормативами, прописанными в договоре.
Задачи в SLA разделяют по степени критичности: блокирующие ошибки (сайт недоступен) требуют исправления в течение 2-4 часов, некритичные баги (ошибки верстки) исправляются в течение 12-24 часов, а плановые доработки выполняются в порядке очереди согласно утвержденному бэклогу.
В SLA техподдержки сайта обязательно фиксируют: время реакции (First Response Time), время устранения неисправности (Resolution Time) и коэффициент доступности сайта (Uptime). Также важно прописать график работы поддержки (например, 24/7 или 8/5) и каналы связи для подачи заявок.
SLA (Service Level Agreement) — это официальное соглашение, которое определяет стандарты качества обслуживания сайта. Он необходим для фиксации времени реакции на инциденты, гарантии доступности сервера и установления финансовой ответственности подрядчика за несоблюдение сроков.




